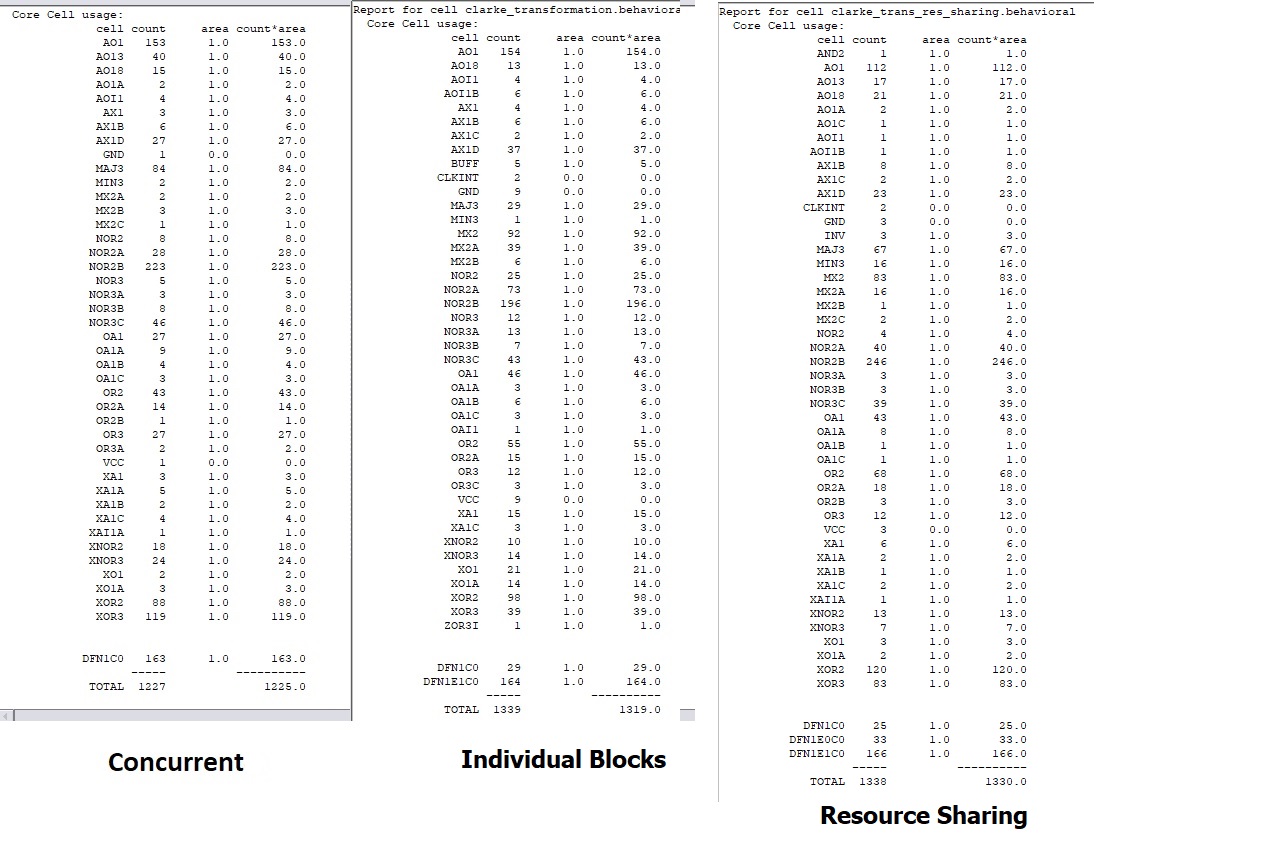
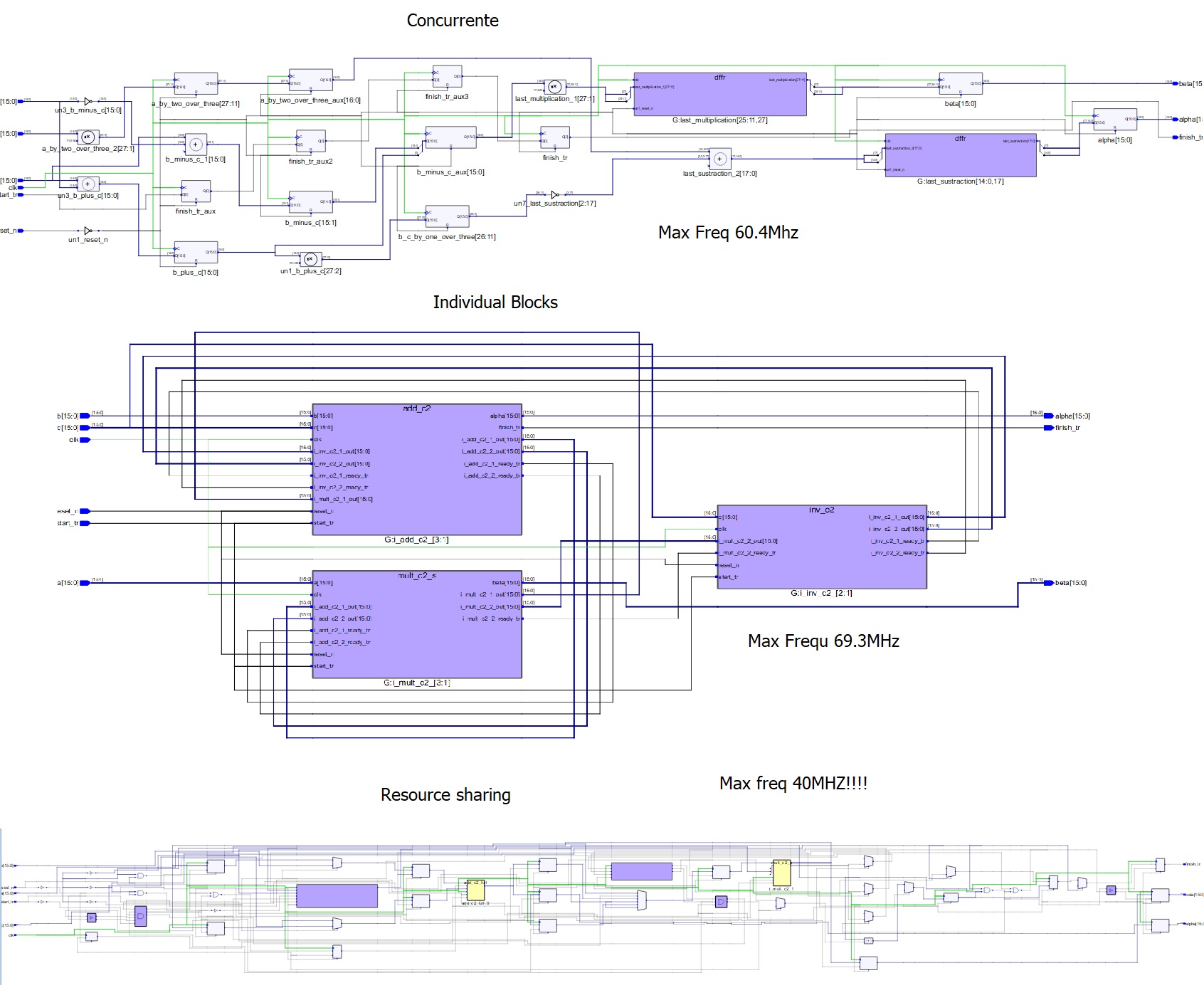
Hi I'm implementing an equation on VHDL. In this case a Clarke transformation. I did it in 3 different methods. - First one by a concurrent process using auxiliary signals to register the intermediate caclulations. - Second one using a sublock for the adder and multiplier and and instantiating as many as needed pipelining with start/end signals - Third usign sublocks for adder and multiplier but implementing some resource sharing logic to instantiate only one adder and one multiplier. The result is almost he shame in therms of resources! How is it possible? Even the resource sharing method estimated freqency is lower than the other methods.. I attach the resource logs and the RTL view on synplify Seems that Symnplify applies some kind of resource sharing on the individual block model?? (in this one there is an inverter for the substracttion instead of a full adder, but it does not have so much differnece) On the concurrent methot the resources shouldn't be much higher as it implements adders and multipliers individually? Thanks in advance
Attached files:
-

recursos_Clarke.jpg
240 KB -

clarke_rtl.jpg
370 KB
Carlos wrote: > The result is almost he shame in therms of resources! How is it > possible? Why not? Your design leeds on all three strategies to a comparable solution. Normally there exists a critical path in every design, so no tool can perform magic. The maximum frequency after synthesis is only a hint. Real numbers exists right after Place&Route. They can differ in range 50% to 200% from the frequency estimation after the synthesis step. Duke
Carlos wrote: > The result is almost he shame in therms of resources! Kind of correct, although its only a typo... ;-) > How is it possible? Obviously doesn't your descriptions of the formula differ very much one from the other. Because even when you describe the algo in concurrent or a 1, 2 or even in a 3 process code, it has to perform almost the same calculations. > Even the resource sharing method estimated freqency is lower than the > other methods.. Looks linke there is almost no resseorce sharing at all. For timing analysis: do a STA and look for the (already mentioned) critical path.
>>Obviously doesn't your descriptions of the formula differ very much one
from the other. Because even when you describe the algo in concurrent or
a 1, 2 or even in a 3 process code, it has to perform almost the same
calculations.
Yes, I know. But in concurrent and pipelined blocks aproach it uses
independent adders and multipliers for each operation.
In resource sharing approach it uses only one adder an one multiplier.
The resource sharing is done by me. Implementing quind of a state
machine to decide when use the adder and the multiplier. I obtained
better results using CASE instead of IF/Else statements
But I didnt't take into account that with resource sharing approach I
was using parallel multipliers instead os serialiced form. Parallel
multipliers use more logic but are faster than serial ones.
With this two improvements the area reduced to almost 50% and the
frequency returned to around max 60MHz
But it becomes to slow on simulation to implement serial multipliers and
respurce sharing...
Thanks
Regards
Carlos wrote: > But I didnt't take into account that with resource sharing approach I > was using parallel multipliers instead os serialiced form. Parallel > multipliers use more logic but are faster than serial ones. Define "serial multiplier" and "parallel multiplier". Because the toolchain will simply use the built in silicon multipliers in the FPGA. What you could do is to use such 1 multiplier over several clock cycles for several independent multiplications. But then you have to multiplex the factors and the result which generates additional logic around that 1 multiplier as tradeoff.
I'm not using built in silicon multipliers like Mult18x18 or similar. I'
just using combinational logic. Indeed Proasic3 does not have
multipliers.
Parallel multiplication is done by the numeric.std library itself.
Operation done in one cycle. And then it is registreded and
scaled(discarding lower bits for floating point operations)
-- Multiply operation
mult_data <= signed(a) * signed(b);
---
elsif rising_edge(clk) then -- rising clock edge
p <= mult_data(mult_data'high downto g_bit_div_p);
Serial is done by quite more complex code. Accumulate, siftt, xor...
Please log in before posting. Registration is free and takes only a minute.
Existing account
Do you have a Google/GoogleMail account? No registration required!
Log in with Google account
Log in with Google account
No account? Register here.