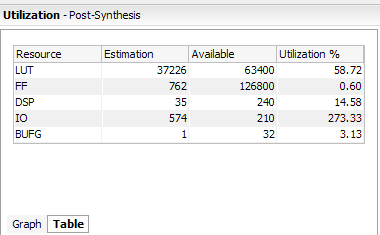
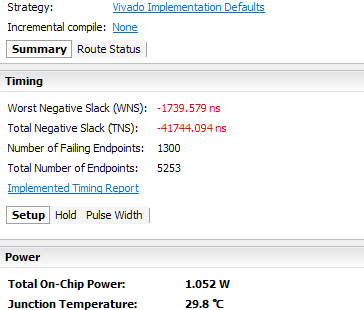
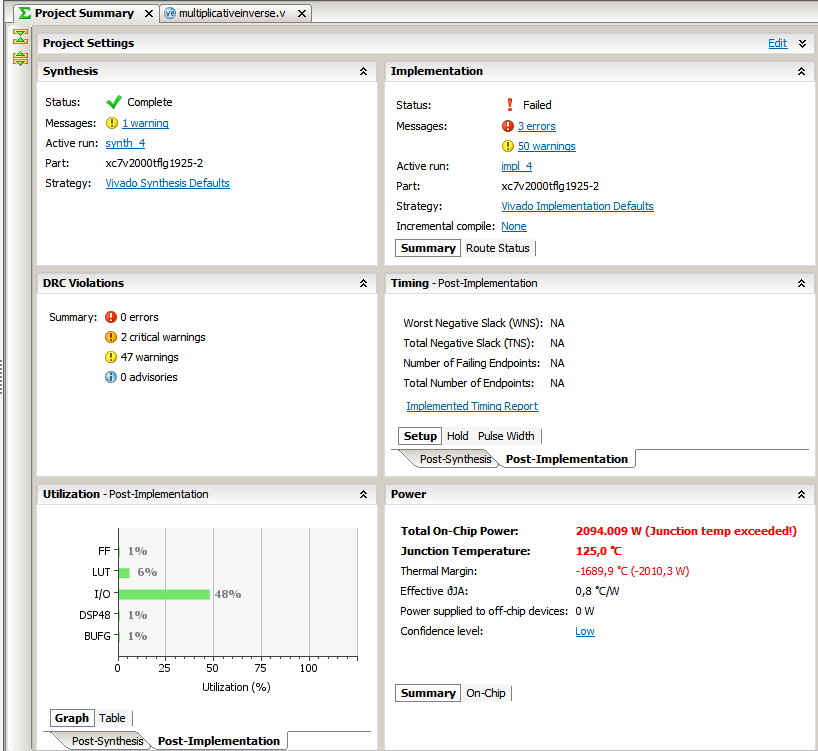
Hi I am working on a multiplicative inverse algorithm to implement ecc algorithm. I have made the Verilog code for this, The simulation is working properly but the synthesis report is showing LUT utilization 76776 out of 63400.I have applied DSP attribute to reduce no of LUTs and it reduces from 78000 to 76776 I am targeting Nexys4DDR FPGA board Please provide any solution to minimize LUT utilization.I have attached project summary and utilization report of this code.
1 | (* use_dsp48 = "yes" *) |
2 | module multiplicative_inverse #(parameter n = 190)(clk, reset, enable, p, a, x, result_ready); |
3 | input clk, reset, enable; |
4 | input wire [n-1:0] p; |
5 | input wire [n-1:0] a ; |
6 | output reg [n-1:0] x; |
7 | output reg result_ready; |
8 | |
9 | //flag to initialize variables when reset
|
10 | reg flag; |
11 | |
12 | reg [n-1:0] Y; |
13 | reg [n-1:0] D; |
14 | reg [n-1:0] B; |
15 | |
16 | wire Y0 = (Y[0] == 0) ? 1 : 0; |
17 | wire D0 = (D[0] == 0) ? 1 : 0; |
18 | |
19 | reg flagY0 = 1; |
20 | reg flagD0 = 1; |
21 | |
22 | |
23 | |
24 | |
25 | |
26 | always @ (posedge clk) begin |
27 | if (reset) begin |
28 | x <= 0; |
29 | flag <= 1; |
30 | result_ready <= 0; |
31 | end
|
32 | else begin |
33 | if(result_ready) begin |
34 | result_ready <= 0; |
35 | flag <= 1; |
36 | end
|
37 | else //Initialize the variables |
38 | if (flag || enable) begin |
39 | Y <= a; |
40 | D <= p; |
41 | B <= 1; |
42 | x <= 0; |
43 | flag <= 0; |
44 | end
|
45 | else begin |
46 | |
47 | if (Y != 0) begin |
48 | |
49 | if (Y0 && flagY0) begin |
50 | |
51 | Y = Y >> 1; |
52 | |
53 | |
54 | B = (B + (B[0]*p)) >> 1; |
55 | |
56 | end //end if |
57 | |
58 | else begin |
59 | flagY0 = 0; |
60 | end
|
61 | if (D0 && flagD0) begin |
62 | |
63 | D = D >> 1; |
64 | x = (x + (x[0]*p)) >> 1; |
65 | |
66 | end //end if |
67 | else begin |
68 | flagD0 = 0; |
69 | end
|
70 | if((flagY0 == 0) && (flagD0 == 0)) begin |
71 | |
72 | if (Y >= D) begin |
73 | Y = Y - D; |
74 | if(B < x) |
75 | |
76 | B = B + p ; |
77 | B = (B - x) % p; |
78 | |
79 | end
|
80 | else begin |
81 | if(D < Y) |
82 | D = D + p; |
83 | D = D - Y; |
84 | if(x < B) |
85 | x = x + p; |
86 | x = (x - B) % p; |
87 | end //else |
88 | flagY0 = 1; |
89 | flagD0 = 1; |
90 | end //else |
91 | end //end if |
92 | else begin |
93 | result_ready <= 1; |
94 | end
|
95 | end
|
96 | end
|
97 | end
|
98 | endmodule
|